
Kafka Producer Warmup으로 첫 Event 발행 지연 줄이기
Spring으로 웹 서비스를 운영하다 보면, 배포 직후 첫 호출에 대한 응답이 평소보다 눈에 띄게 오래 걸리곤 한다. 이 요인은 정말 다양한데, 공통점은 응답에 필요한 동작들이 eager보다는 lazy하게, 즉 실제 호출을 받았을 때가 되어서야 이루어진다는 것이다. kafka producer 역시 마찬가지다.
업무 중 kafka를 통해 event를 publish하는 구조를 새로 설계했다. 평소에는 publish 자체가 약 1~5ms 이내에 완료된 반면, 서비스를 배포한 후 첫 event publish는 약 600~800ms가 소요되는 것을 확인하였다. 배포 후 최초 1회에 한해 응답이 지연되는 것이므로 전체 비중 상 매우 미비하지만, 배포를 더 자주 진행할수록 지연되는 event publish의 비중도 늘어난다. 이는 그만큼 사용자가 서비스 이용 중 불편을 겪는 일이 늘어난다는 뜻이 된다.
서비스가 ‘사용 가능’으로 분류되기 전에 미리 필요한 행동을 하는 것을 warmup이라고 한다. 즉, 앞에서 언급한 lazy한 일부 로직을 의도적으로 호출하는 등의 행동으로 eager와 같이 준비해 두는 것이다. kafka publisher 역시 warmup을 할 수 있는 방법을 찾아 적용하였고, 최초 발행을 20ms 정도로 눈에 띄게 감소시킬 수 있었다.
위의 경험을 바탕으로, kafka publisher의 첫 event publish가 눈에 띄게 지연되는 것을 파악하고, 이를 해결하는 방법을 단계적으로 소개한다. kafka의 기본적인 동작 원리에 대해 알고 있으면 좋다.
모든 예제 코드는 GitHub Repository - kafka-warmup-example에서 확인 및 실행할 수 있다.
기존 구조 - warmup 없이 이벤트 발행
아래와 같이 간단한 API가 있다.
@RestController
@RequestMapping("/events")
class EventController(
private val kafkaTemplate: KafkaTemplate<String, String>,
@param:Value("\${kafka.topic:events}") private val topic: String
) {
@PostMapping
fun publishEvent(@RequestBody request: EventRequest) {
kafkaTemplate.send(topic, request.message)
}
}
data class EventRequest(
val message: String
)
이 코드의 역할은 매우 간단하다. 규격에 맞추어 /events에 HTTP POST 요청을 보내면, 해당 message를 주어진 topic에 발행한다.
local 환경에서 직접 확인해 보자. 예시 코드의 안내대로 Docker Desktop과 Docker Compose가 설치된 환경에서 진행한다.
먼저, kafka, Grafana Tempo, OpenTelemetry Collector, Grafana를 실행한다.
docker-compose up -d
모든 서비스가 올라올 때까지 기다린다.
docker-compose ps
이제 localhost:3000에서 Grafana에 접근할 수 있다.
다음으로 Spring Boot 애플리케이션을 실행한 후, cURL로 POST 요청을 발행해 보자.
curl -X POST http://localhost:8080/events \
-H "Content-Type: application/json" \
-d '{"message": "Hello, Kafka"}'
이벤트가 성공적으로 발행되면, 잠시 후 Grafana Tempo에서 해당 trace를 확인할 수 있다.

하나의 trace 아래에 2개의 span이 묶여 있다. trace와 span은 간단히 말하자면 1:N 관계로, 하나의 HTTP transaction (trace) 아래에 여러 개의 액션 (DB 조회, 외부 API 호출)이 각각 span으로 정의된다. 여기서는 event publish가 하나의 span이다.
전체 trace는 384.51ms가 소요되었고, 그 중 event publish span이 191ms 소요되었다. 예시를 위해 간략하게 만든 코드임에도 불구하고 응답 시간이 짧지는 않은 편이다.
같은 API를 한번 더 호출해 보자.
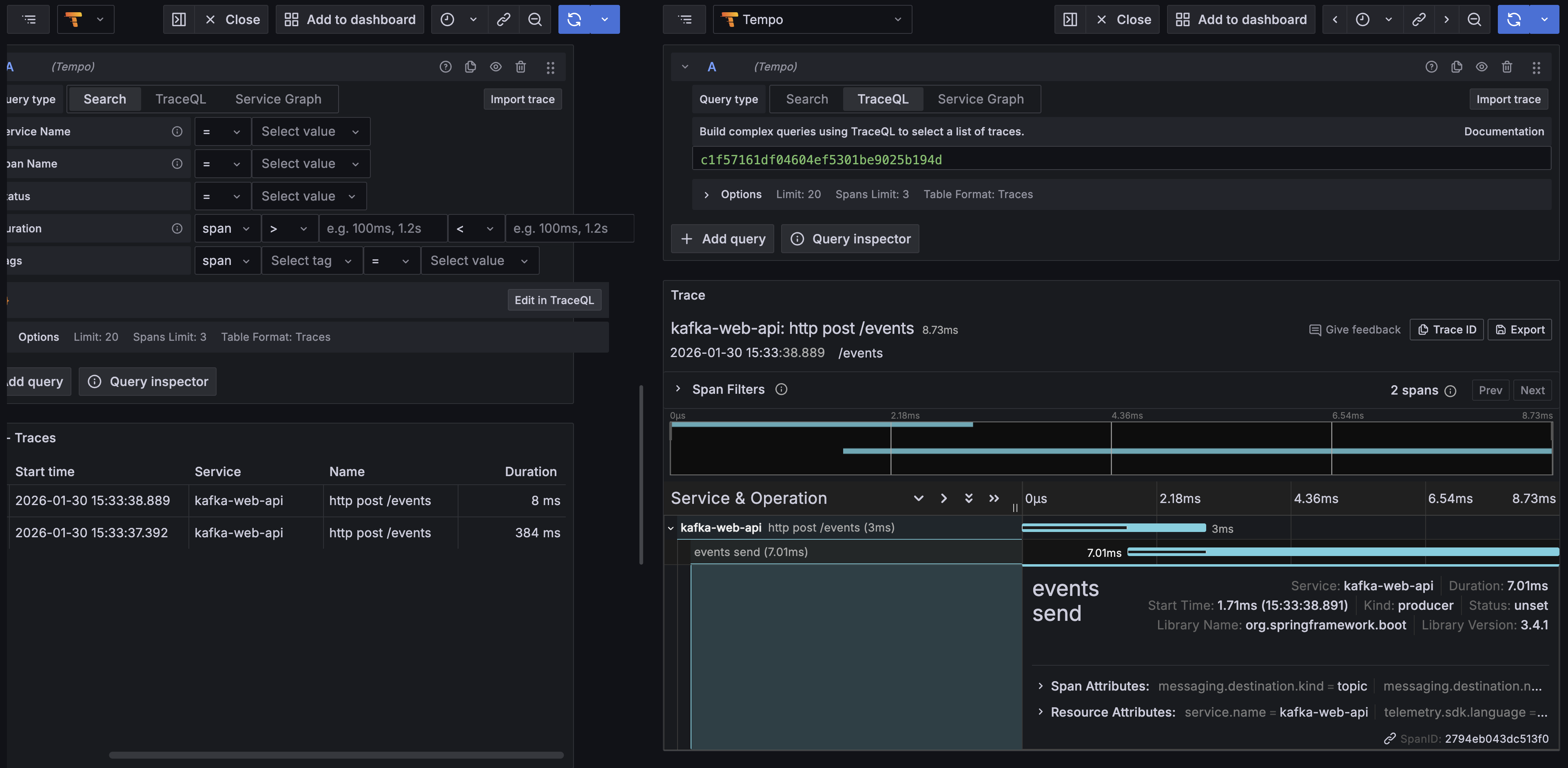
확연히 짧아진 시간을 확인할 수 있다. 전체 trace가 8ms 소요되었고, event publish span은 무려 7.01ms이다. 즉, 애플리케이션 시작 후 첫 event publish가 확연히 오래 소요되는 것을 확인할 수 있다.
Warmup 적용하기
앞서 확인한 것처럼 producer가 event를 한 번 publish 한 후에는 시간이 확연히 줄어드는 것을 확인할 수 있다. 따라서, 실제로 서비스에 투입하기 전에 이벤트를 한 번 발행하면 되지 않을까? 하는 생각이 들었다.
물론 해당 토픽에 실제 이벤트를 발행하는 것은 좋은 생각이 아니다. 배포하는 팟의 수만큼 해당 토픽에 쓰레기 이벤트가 쌓인다면, consumer에서 이를 별도로 구분하는 등, 더 안 좋은 설계가 된다. 즉, event publish에 필요한 모든 걸 하되 event publish만 하지 않는(?) 동작을 생각하게 되었다.
ApplicationRunner로 warmup 실행하기
Spring Boot에는 ApplicationRunner라는 인터페이스가 있다.
SpringApplication이 실행될 때, ApplicationRunner를 구현한 Spring Bean이 실행 (run)된다.
아래와 같이 ApplicationWarmupRunner를 작성하였다.
@Component
class ApplicationWarmupRunner(
private val useCaseList: List<ApplicationWarmupRunnerUseCase>,
) : ApplicationRunner {
private val logger = LoggerFactory.getLogger(ApplicationWarmupRunner::class.java)
override fun run(args: ApplicationArguments) {
logger.info("Starting warmup - ${useCaseList.size} runners")
useCaseList.forEach { useCase ->
runCatching {
logger.info("Warming up ${useCase.runnerName}")
useCase.warmup()
}.onFailure { e ->
logger.warn("Failed to warm up ${useCase.runnerName}", e)
}
}
logger.info("Finished warmup")
}
}
interface ApplicationWarmupRunnerUseCase {
val runnerName: String
fun warmup()
}
ApplicationWarmupRunnerUseCase의 구현체가 bean으로 등록되면, ApplicationWarmupRunner에서 구현체들의 warmup()을 각각 실행시키는 구조다.
partitionsFor()를 통해 warmup 하기
ApplicationWarmupRunnerUseCase의 구현로, ApplicationWarmupKafkaUseCase를 작성하였다.
@Component
@ConditionalOnProperty(name = ["kafka.warmup.enabled"], havingValue = "true") // 1
class ApplicationWarmupKafkaUseCase(
private val kafkaTemplate: KafkaTemplate<String, String>,
@param:Value("\${kafka.topic}") private val topic: String, // 2
) : ApplicationWarmupRunnerUseCase {
override val runnerName = "kafka"
override fun warmup() {
val topics = listOf(topic)
topics.forEach { _ -> kafkaTemplate.partitionsFor(topic) } // 3
}
}
코드를 살펴 보자.
@ConditionalOnProperty()를 통해, 해당 component의 활성화 여부를 조절할 수 있도록 하였다. 실제 코드에서는 필요 없지만, warmup 여부에 따른 결과를 쉽게 비교할 수 있도록 추가하였다.application.yml에 정의한 topic 이름을 불러오도록 하였다.kafkaTemplate.partitionsFor(topic)을 호출하였다. 이를 통해 warmup이 이루어진다. 뒤에서 자세히 알아본다.
요약
지금까지의 접근을 요약하면,
- producer가 시작할 때 특정 topic에 event publish와 같은 효과를 선행하여, 실제 event publish 시 지연을 예방한다.
- Spring Boot의
ApplicationRunner구현체를 작성하여, warmup usecase 를 호출하도록 하였다. ApplicationWarmupKafkaUseCase를 작성하여, 1에서 의도한 event publish 효과를 만들었다.
이제 이 작업이 실제 효과가 있는지 확인해 보자.
새 구조 - kafka warmup 후 이벤트 발행
application.yml에서 kafka.warmup.enabled를 true로 적용해 주자.

이후 Spring Boot 애플리케이션을 다시 실행해 준다. docker 관련 내용은 아까 켜 둔 그대로 유지하면 된다.

‘Warming up kafka’ 후에 kafka 관련 로그가 길게 올라오는 것을 확인할 수 있다.

완료된 후 producer 관련 로그가 출력된 후, ‘Finished warmup’을 확인할 수 있다.
이제 마찬가지로 cURL로 POST 요청을 발행한다.
curl -X POST http://localhost:8080/events \
-H "Content-Type: application/json" \
-d '{"message": "Hello, Kafka"}'
이후 Grafana에서 확인해 보자.
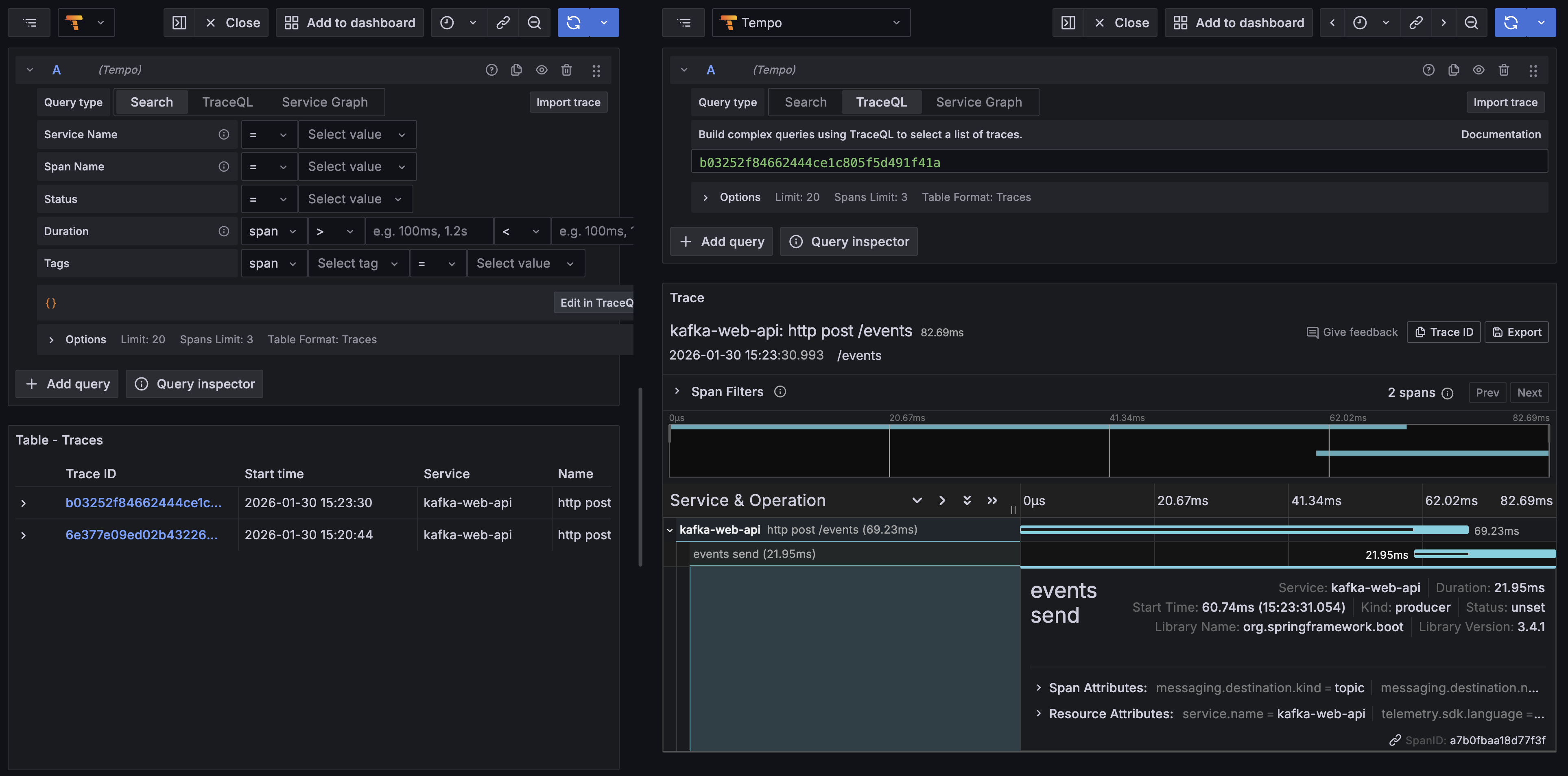
warmup이 효과가 있었다! 비교해 보면 아래와 같다.
| 구분 | trace 총 시간 (ms) | kafka event publish span (ms) |
|---|---|---|
| warmup 없음 | 384.51 | 191.28 |
| warmup 있음 | 82.69 | 21.95 |
| (참고) warmup 없음, 2회차 | 8.73 | 7.01 |
warmup을 진행했음에도, warmup 없을 때의 2회차 때보다는 시간이 오래 걸린다. 이는 event message에 대한 serializer 동작, interceptor 로직 실행, class loading 등이 필요하기 때문이다. 그럼에도 최초 호출 시 지연을 큰 폭으로 감소시킨 것은 틀림없다.
partitionsFor() 알아보기
kafka의 send()와 비교해서, partitionsFor()의 역할과 과정에 대해 알아보자.
partitionsFor() 흐름 파악
partitionsFor()의 구현체는 아래와 같이 되어 있다.
// org.springframework.kafka.core.KafkaTemplate
@Override
public List<PartitionInfo> partitionsFor(String topic) {
Producer<K, V> producer = getTheProducer();
try {
return producer.partitionsFor(topic);
}
finally {
closeProducer(producer, inTransaction());
}
}
우선, getTheProducer()를 통해 producer 정보를 가져온다. 이 때 topic은 넘기지 않는다.
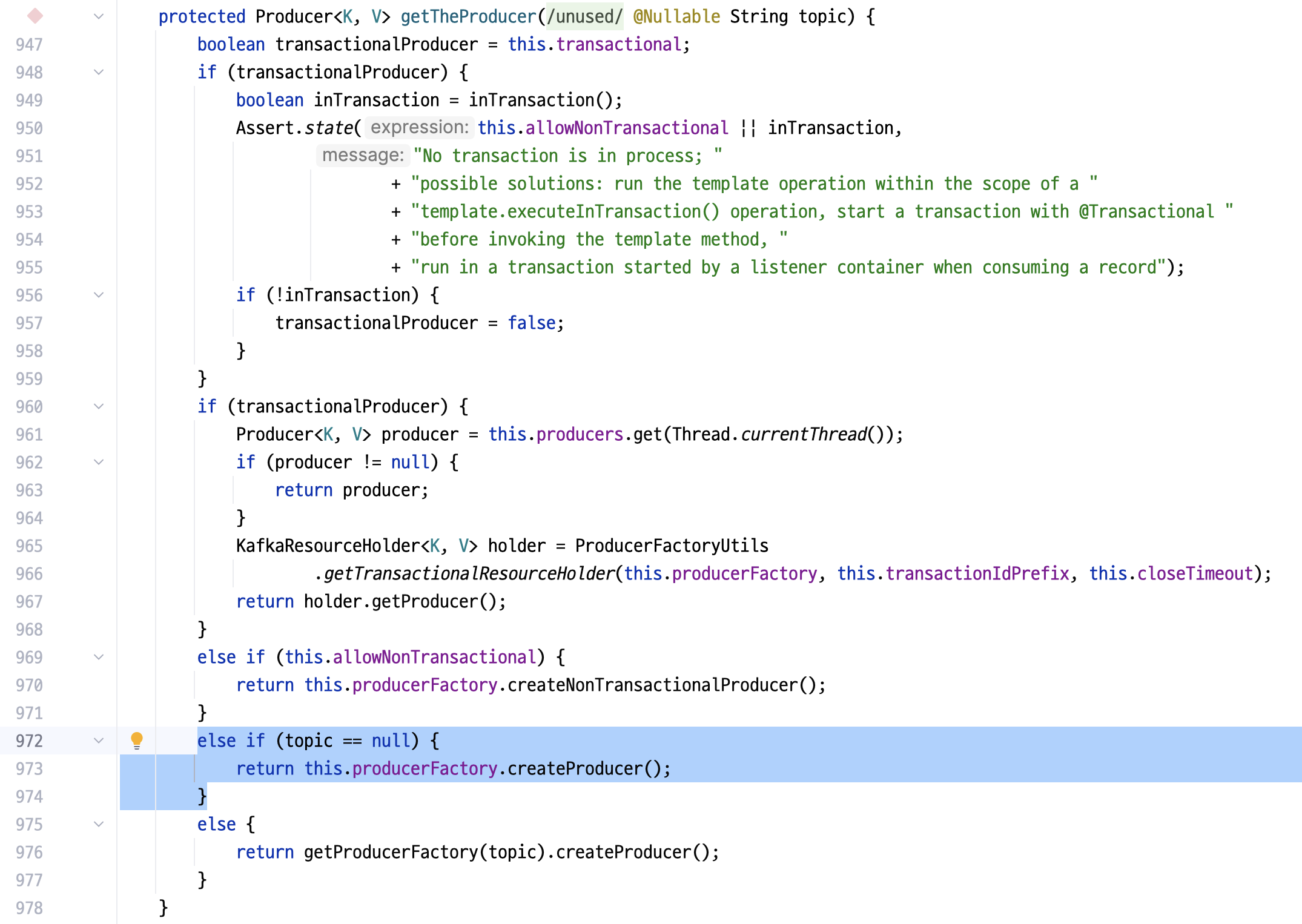
코드가 복잡해 보이지만, debugger를 통해 확인해 보면 단순히 producer를 factory를 통해 생성한다. 즉, 아래와 같이 요약할 수 있다.
// org.springframework.kafka.core.KafkaTemplate
protected Producer<K, V> getTheProducer(@SuppressWarnings("unused") @Nullable String topic) {
return this.producerFactory.createProducer();
}
이 때 생성되는 Producer는 singleton으로, 최초 1회 생성 후 재활용된다.
다음으로, 호출되는 producer.partitionsFor(topic)을 확인한다.

주어진 topic에 대해 partition metadata를 받아 온다.
// package org.apache.kafka.clients.producer.KafkaProducer
@Override
public List<PartitionInfo> partitionsFor(String topic) {
Objects.requireNonNull(topic, "topic cannot be null");
try {
return waitOnMetadata(topic, null, time.milliseconds(), maxBlockTimeMs).cluster.partitionsForTopic(topic); // focus
} catch (InterruptedException e) {
throw new InterruptException (e);
}
}
focus로 주석 처리한 곳의 동작 방식은 아래와 같다.
- 캐시되지 않았다면, metadata 요청을 호출한다.
- metadata를 받아올 때까지 block하고, 주어진 시간 내에 받아오지 못하면 timeout 한다.
즉, 외부 I/O가 실제로 이루어지고, 값을 받아올 때까지 block되기 때문에 최초 호출 시 시간이 오래 걸린다. block 된 동안, bootstrap 서버와의 TCP connection, SSL/TLS handshake 및 SASL authentication이 진행된다.
send() 흐름 파악
send()는 아래와 같이 구현되어 있다.
// org.springframework.kafka.core.KafkaTemplate
@Override
public CompletableFuture<SendResult<K, V>> send(String topic, @Nullable V data) {
ProducerRecord<K, V> producerRecord = new ProducerRecord<>(topic, data);
return observeSend(producerRecord);
}
이 흐름을 따라가 보자.
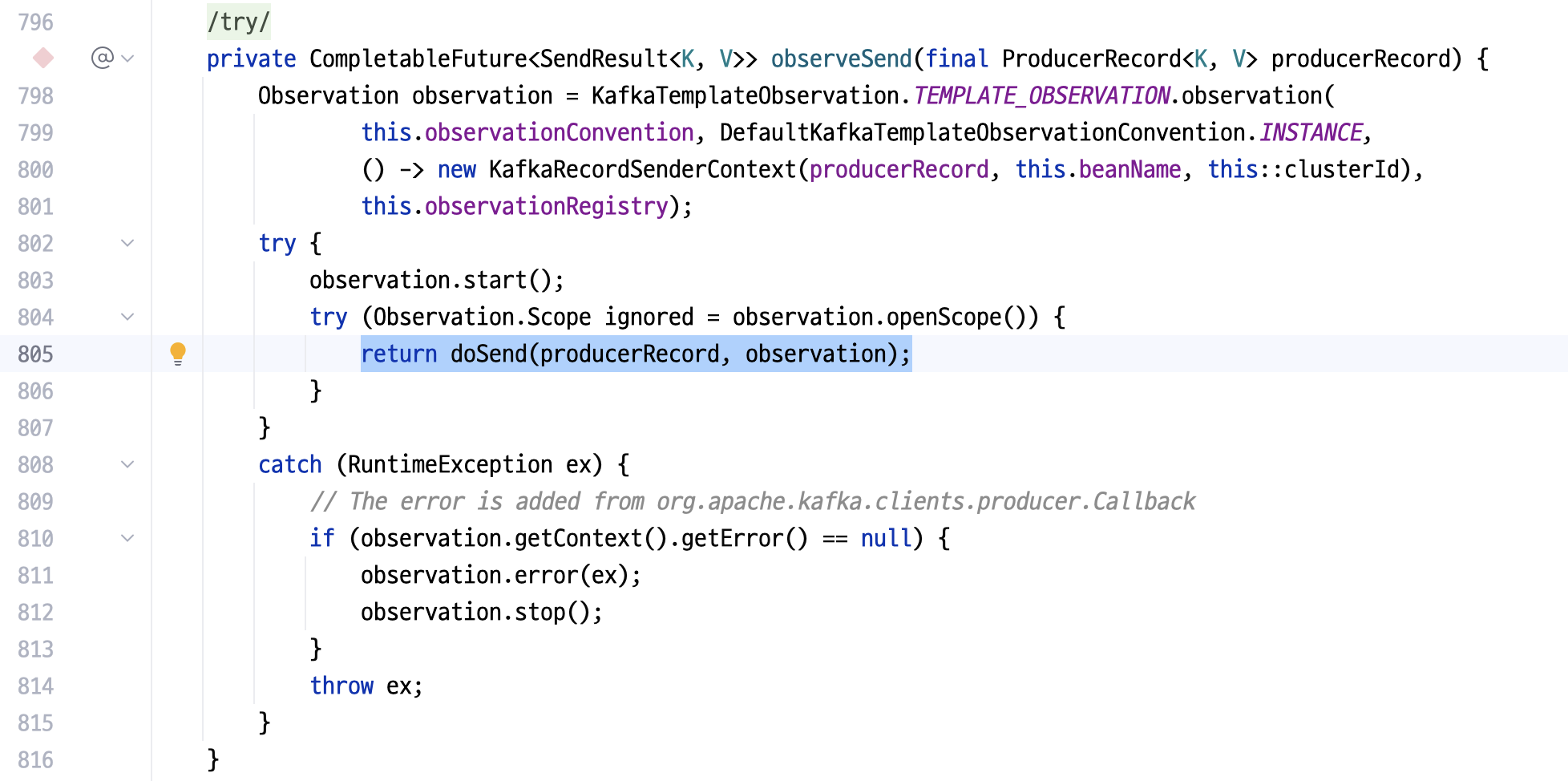
실제 이벤트 발행은 doSend()를 따라간다.
// org.springframework.kafka.core.KafkaTemplate
private CompletableFuture<SendResult<K, V>> observeSend(final ProducerRecord<K, V> producerRecord) {
Observation observation = // ...
try {
observation.start();
try (Observation.Scope ignored = observation . openScope ()) {
return doSend(producerRecord, observation); // focus
}
}
// ...
}

여기서 send()를 따라 간다.
// org.springframework.kafka.core.KafkaTemplate
protected CompletableFuture<SendResult<K, V>> doSend(final ProducerRecord<K, V> producerRecord, Observation observation) {
final Producer<K, V> producer = getTheProducer(producerRecord.topic());
// ...
Future<RecordMetadata> sendFuture =
producer.send(interceptedRecord, buildCallback(interceptedRecord, producer, future, sample, observation)); // focus
// ...
return future;
}
따라간 KafkaProducer.send()는 아래와 같이 생겼는데, (붙어 있는 javadoc이 너무 길어 캡쳐는 생략하였다)
// package org.apache.kafka.clients.producer.KafkaProducer
@Override
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback); // focus
}
이 때 doSend()를 확인해 보자.

// package org.apache.kafka.clients.producer.KafkaProducer
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
KafkaProducer.AppendCallbacks appendCallbacks = new KafkaProducer.AppendCallbacks(callback, this.interceptors, record);
try {
throwIfProducerClosed();
// first make sure the metadata for the topic is available
long nowMs = time.milliseconds();
KafkaProducer.ClusterAndWaitTime clusterAndWaitTime;
try {
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs); // focus
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
}
}
익숙한 메서드가 나왔다. waitOnMetadata()를 통해 metadata를 불러온다. 앞서 partitionsFor() 때와는 다르게 두 번째 인자 (Integer partition)가 record.partition()의 값으로 전달되지만, 메타데이터를 가져오는 것은 크게 다르지 않다.
결론
send()를 호출하면 metadata를 불러 오는 과정이 포함되고, 이는 partitionsFor()에서 불러오는 것과 같다. partitionsFor()를 통해 미리 warmup을 해 두면, 실제 send() 없이도 metadata를 미리 불러와 캐싱해 둘 수 있다.
결론
많은 서비스들이 무중단 배포가 가능하다고 말한다. 그만큼 배포를 더 작게, 자주 진행할 수 있다는 장점이 있지만, cold start와 같은 단점 역시 수반된다. 완벽하게 개선하지 못하더라도, SW 엔지니어로서 인지하고 개선할 수 있는 부분은 개선해야 한다. kafka는 특히 MSA 환경에서 많이 사용되는 만큼, producer의 warmup을 한 번 고려해 보자.
예제에 활용한 코드는 Claude Code와 함께 만들었다. 이번처럼 어떤 성능 개선 케이스를 소개하는 경우 이를 실제로 돌려볼 수 있는 예제 코드가 있으면 좋겠다고 생각하는데, AI를 활용해서 이를 더 완성도 있게 만들 수 있어 만족스럽다.
References
- Stack Overflow- Why kafka producer is very slow on first message?

Leave a comment